Money Heist
is a Spanish heist crime drama television series created by Álex Pina. The series traces two long-prepared heists led by the Professor (Álvaro Morte), one on the Royal Mint of Spain, and one on the Bank of Spain, told from the perspective of one of the robbers, Tokyo (Úrsula Corberó). The narrative is told in a real-time-like fashion and relies on flashbacks, time-jumps, hidden character motivations, and an unreliable narrator for complexity.
“Money Heist” (“La Casa de Papel”) is a Spanish series.
“Money Heist” is the most in-demand series globally across all platforms, according to Parrot Analytics
IMDB rating: 8.3
Money Heist: Netflix only paid $2 to buy ‘La Casa de Papel’ (assumed earning 365 crores to 401 crores not officially declared)
Season1: $3.0 to 3.3 million
Season2: $4.3 to 7.8 million
Season3: $9 to 9.4 million
Season4: $9.7 to 10.3 million
Season5(partA&partB): $11.1 to 15.7 million
Total budget $46.2 million
Rio: 55000+ Denver: 55000+ inspector Raquel: 6500 +
inspector alisha: 65000 + Helsinki 70000 + Nairobi: 75000, +Tokyo: 100000, + Berlin: 100000, + Professor: 120000)×8
=705,000
Even if the actors get 1% of net profit total earning per episode, for 8episodes series the income will be $564,000,000 fifty-six million four hundred thousand dollars ~ or ~ 38513622416.8 crores ($rate 74.3).
#Import the following libraries
#Loading the data sets
#Creating the word cloud

#Finding the frequency distinct in the tokens
#To find the frequency of top 10 words
#tokens
#Finding the sentiments of a sentence
#Extracting only text field
#Checking whether there are any empty values in data frame
# Displaying the unique names
#Data Cleaning
#Expand Contractions
#Contractions are the shortened versions of words like don’t for do not and how’ll for how will etc. We need to expand it.
# Regular expression for finding contractions
# Function for expanding contractions
# Expanding Contractions in the reviews and storing as a seperate column
#Store the cleaned reviews in the new column
##Lowercase the reviews
#Remove digits and words containing digits
#Removing Punctuations
#Preparing Text Data for Exploratory Data Analysis (EDA)
#1) Stopwords Removal : Removing the most common words of a language like ‘I’, ‘this’, ‘is’, ‘in’
#2) Lemmatization : reducing a token to its lemma. It uses vocabulary, word structure, part of speech tags, and grammar relations to convert a word to its base form using builtin library like spacy, nltk etc.
#3) Create Document Term Matrix
#Removing Extra Spaces
# Python program to generate WordCloud

#parts of Speach Tagger
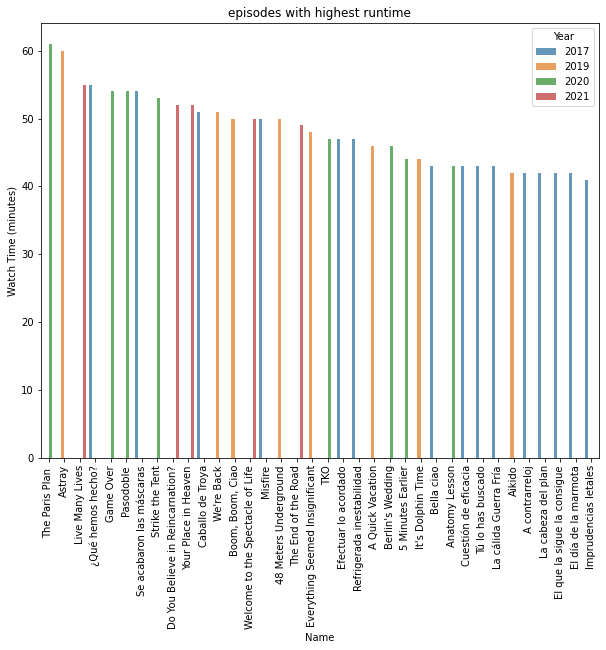
plt.figure(figsize=(10,8))
sns.barplot(x=”Name”,y=”Watch Time (minutes)”,data=df.sort_values(“Watch Time (minutes)”,ascending=False),hue=”Year”,alpha=0.75);plt.xticks(rotation=90)
plt.title(“episodes with highest runtime”);plt.show()
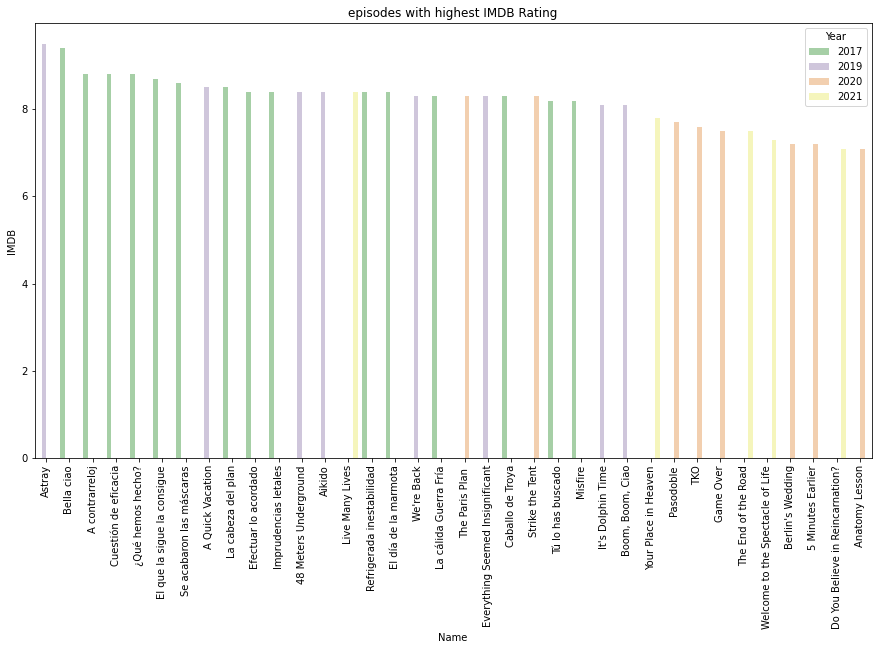
plt.figure(figsize=(15,8))
sns.categorical.barplot(x=”Name”,y=”IMDB”,data=df.sort_values(“IMDB”,ascending=False),hue=”Year”,alpha=0.75,palette=”Accent”);plt.xticks(rotation=90)
plt.title(“episodes with highest IMDB Rating”);plt.show()