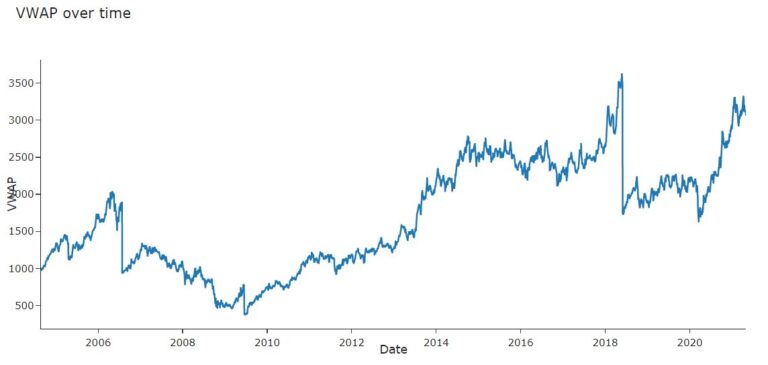
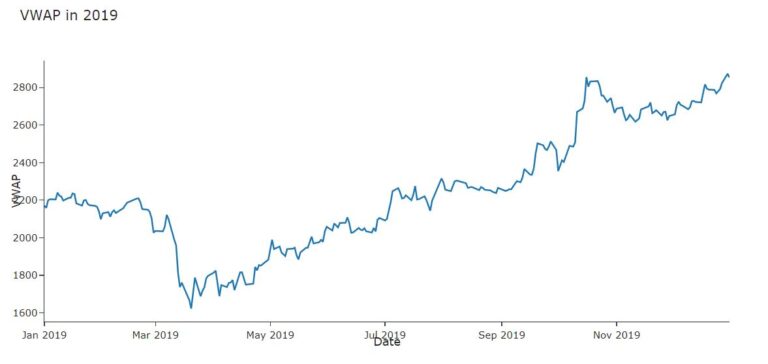
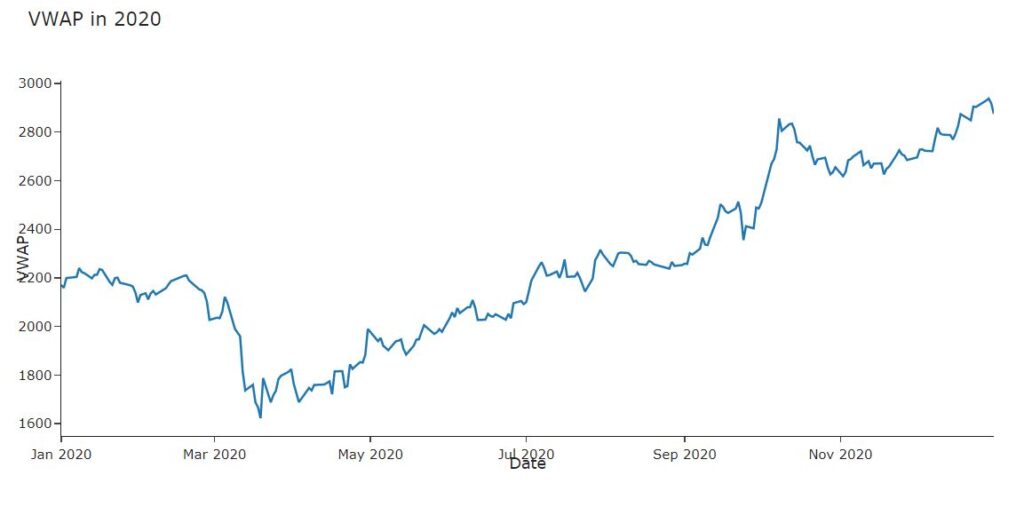
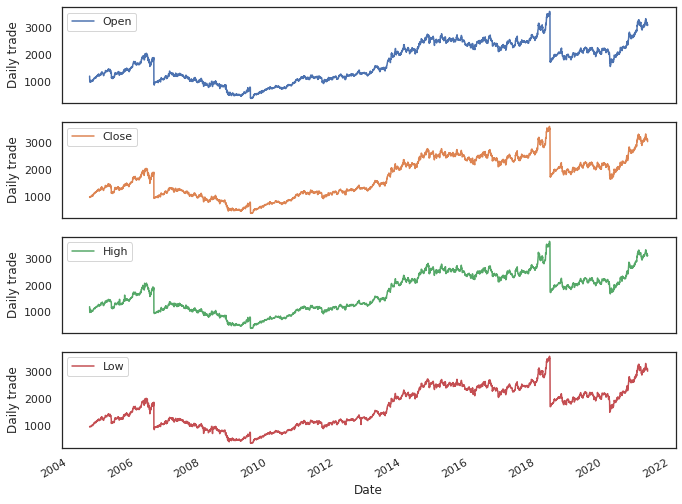
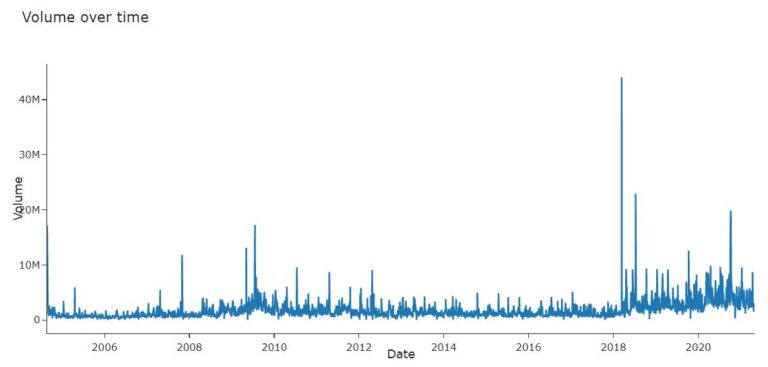
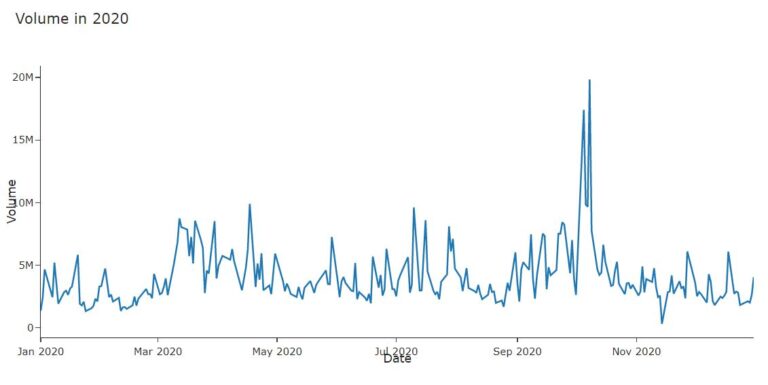
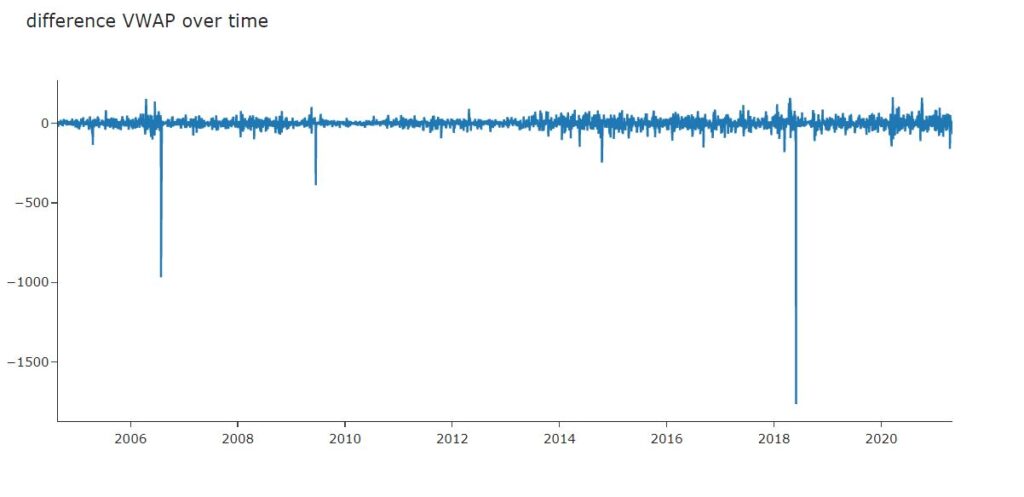
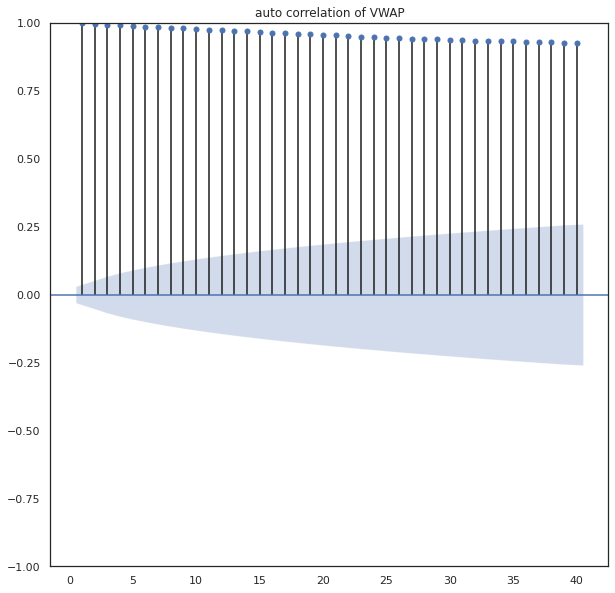
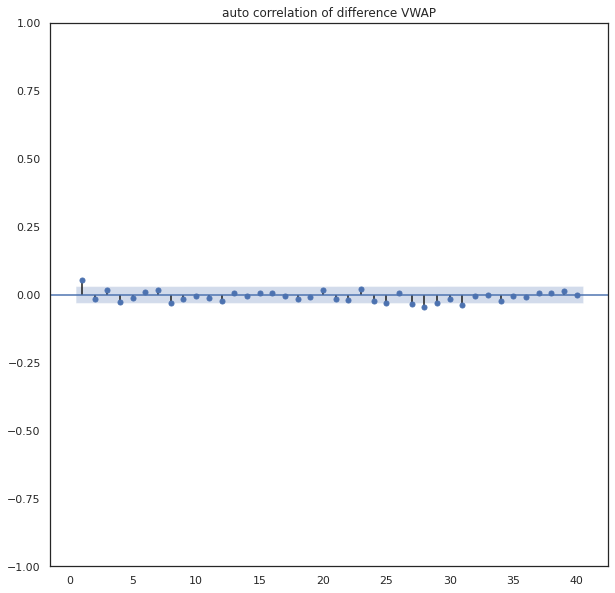
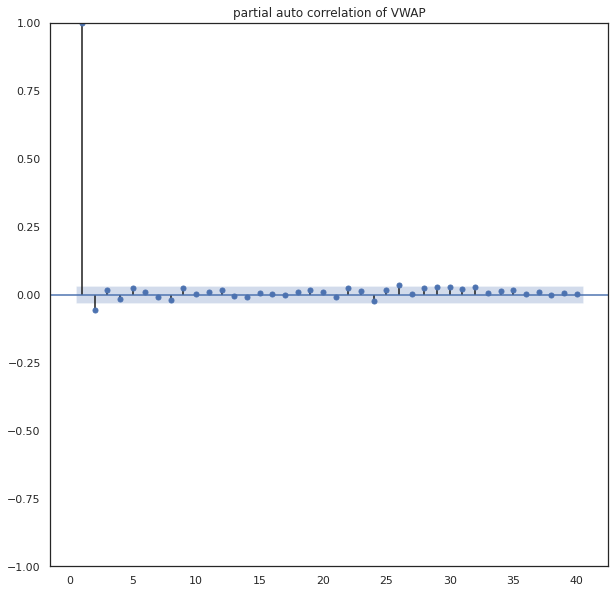
#Dicky Fuller Test
The Augmented Dickey-Fuller test is a type of statistical test called a unit root test.
The intuition behind a unit root test is that it determines how strongly a time series is defined by a trend It uses an autoregressive model and optimizes an information criterion across multiple different lag values.
The null hypothesis of the test is that the time series can be represented by a unit root, that it is not stationary (has some time-dependent structure). The alternate hypothesis (rejecting the null hypothesis) is that the time series is stationary.
Null Hypothesis (H0): If failed to be rejected, it suggests the time series has a unit root, meaning it is non-stationary. It has some time dependent structure.
Alternate Hypothesis (H1): The null hypothesis is rejected; it suggests the time series does not have a unit root, meaning it is stationary. It does not have time-dependent structure.
We interpret this result using the p-value from the test. A p-value below a threshold (such as 5% or 1%) suggests we reject the null hypothesis (stationary), otherwise a p-value above the threshold suggests we fail to reject the null hypothesis (non-stationary).
p-value > 0.05: Fail to reject the null hypothesis (H0), the data has a unit root and is non-stationary. p-value <= 0.05: Reject the null hypothesis (H0), the data does not have a unit root and is stationary.
def dicky_fuller_test(x):
result = adfuller(x)
print(‘ADF Statistic: %f’ % result[0])
print(‘p-value: %f’ % result[1])
print(‘Critical Values:’)
for key, value in result[4].items():
print(‘\t%s: %.3f’ % (key, value))
if result[1]>0.05:
print(“Fail to reject the null hypothesis (H0), the data is non-stationary”)
else:
print(“Reject the null hypothesis (H0), the data is stationary.”)
dicky_fuller_test(df[‘VWAP’])
#Seasonal Decompose
from statsmodels.tsa.seasonal import seasonal_decompose
from dateutil.parser import parse
plt.rcParams.update({‘figure.figsize’: (10,10)})
y = df[‘VWAP’].to_frame()
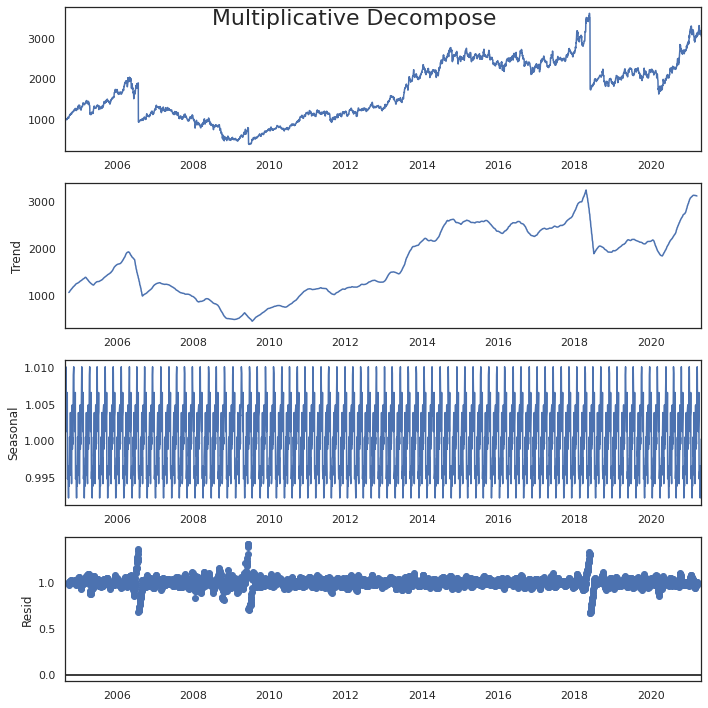
# Multiplicative Decomposition
result_mul = seasonal_decompose(y, model=’multiplicative’,period = 52)
# Additive Decomposition
result_add = seasonal_decompose(y, model=’additive’,period = 52)
# Plot
plt.rcParams.update({‘figure.figsize’: (10,10)})
result_mul.plot().suptitle(‘Multiplicative Decompose’, fontsize=22)
result_add.plot().suptitle(‘Additive Decompose’, fontsize=22)
plt.show()